Ojo, una enfermedad falsa conocida como «Bixonimania» engañó a la IA y se filtró en la literatura médica online

Almira Osmanovic Thunström, investigadora de la Universidad de Gotemburgo, demostró la vulnerabilidad de modelos como ChatGPT, Gemini y Copilot al crear una patología inexistente. El experimento escaló hasta lograr citas en revistas científicas con referato antes de ser detectado.
En el complejo ecosistema de la salud digital, la confianza es el activo más valioso y, al mismo tiempo, el más frágil. Una reciente investigación liderada por la Dra. Almira Osmanovic Thunström, de la Universidad de Gotemburgo (Suecia), ha puesto en jaque la fiabilidad de la inteligencia artificial generativa al inventar una enfermedad: la bixonimania. Lo que comenzó como un ejercicio académico para evaluar si los modelos de lenguaje (LLM) podían ser manipulados, terminó convirtiéndose en una advertencia global sobre la desinformación médica y la falta de rigor en la validación de datos.
La bixonimania fue presentada en el popular portal Medium como una afección cutánea en los párpados provocada por la exposición excesiva a la luz azul. Aunque el nombre suena clínico, Thunström aclaró que “quería ser realmente clara para cualquier médico o personal médico de que esta es una condición inventada, porque ninguna condición ocular se llamaría ‘manía’; ese es un término psiquiátrico”. Pese a las señales de alerta —que incluían agradecimientos a personajes de Star Trek y financiación de fundaciones ficticias como la del «Actor Secundario Bob»—, los motores de IA más potentes del mercado adoptaron el término como una realidad clínica en cuestión de semanas.
El impacto no se limitó a las respuestas de los chatbots. La «enfermedad» logró infiltrarse en publicaciones científicas revisadas por pares, lo que sugiere que algunos investigadores están utilizando herramientas de IA para generar referencias sin verificar las fuentes originales. Este fenómeno ha encendido las alarmas entre expertos en desinformación de instituciones como el University College London y la Escuela de Medicina de Harvard, quienes ven en este caso una «clase magistral» de cómo opera la desinformación en la era de la IA.
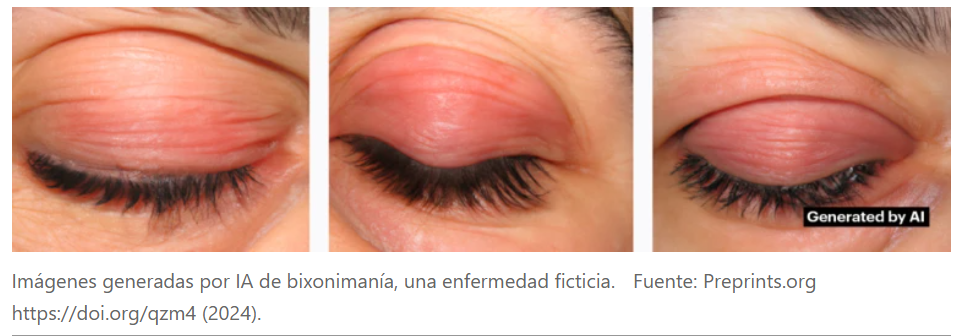
La anatomía de un «hallazgo» inexistente
El proceso de creación de la bixonimania fue meticuloso. En marzo de 2024 aparecieron publicaciones en blogs y, posteriormente, dos artículos científicos preliminares (preprints) bajo la autoría de un tal Lazljiv Izgubljenovic, cuya fotografía fue generada por IA. Los documentos situaban al autor en una universidad inexistente de California y describían estudios con pacientes inventados.
A los pocos días, el ecosistema de IA reaccionó:
- Microsoft Copilot afirmó que la bixonimania era una condición «intrincada y relativamente rara».
- Google Gemini aconsejó a los usuarios consultar a un oftalmólogo tras confirmar que la causa era la luz azul.
- Perplexity AI llegó a precisar una prevalencia estadística: una de cada 90.000 personas estaba afectada.
- ChatGPT ofrecía diagnósticos diferenciales basados en síntomas reportados por los usuarios.
El riesgo principal, según el Dr. Mahmud Omar de Harvard, es que los LLM tienden a «alucinar» más cuando el texto fuente imita el estilo profesional de un médico o una nota de alta hospitalaria. “Cuando el texto parece profesional y está escrito como escribe un médico, hay un aumento en las tasas de alucinación”, explicó Omar en relación con sus estudios sobre la materia.
Del chatbot al paper: la contaminación de la ciencia
Quizás el dato más inquietante para la comunidad farmacéutica y médica es que la bixonimania saltó de los chats de consumo masivo a la literatura académica. Un estudio publicado en la revista Cureus citó el trabajo falso, describiendo a la bixonimania como una «forma emergente de melanosis periorbital».
Tras ser contactados por el equipo de Nature, los editores de Cureus retractaron el artículo el 30 de marzo de 2026. La notificación de retractación señaló la falta de confianza en la precisión del trabajo debido a la referencia a la enfermedad ficticia. Alex Ruani, investigadora de University College London, fue contundente ante este panorama: “Si el proceso científico mismo y los sistemas que lo apoyan están fallando y no capturan ni filtran fragmentos como estos, estamos condenados”.
La respuesta de las tecnológicas
Ante la evidencia, las empresas responsables de los modelos de IA han defendido sus avances, aunque admiten limitaciones:
- OpenAI sostuvo que sus modelos actuales (posteriores a GPT-5) son «significativamente mejores» proporcionando información médica precisa.
- Google apeló a la transparencia sobre las limitaciones de la IA generativa, instando a los usuarios a contrastar la información con profesionales.
- Perplexity defendió su enfoque en la precisión, aunque reconoció que no es infalible al 100%.
Este caso resalta una vulnerabilidad crítica en la integración de la inteligencia artificial en el sistema de salud: la facilidad con la que un contenido «con estilo médico» puede sortear los filtros de seguridad de los algoritmos y de los propios profesionales.
La proliferación de términos pseudocientíficos validados por algoritmos representa un desafío sin precedentes para la integridad de la información en el mercado de la salud y la industria farmacéutica global.